Spielman-Teng’s 2004 paper [ST04] on almost-linear Laplacian linear solver has been divided and re-written into three very technically involved papers [ST08a], [ST08b] and [ST08c]. I am planning to write memos for all of them, while this post is the Part I for the second paper [ST08b: Spectral Sparsification of Graphs].
Outline
The goal of [ST08b] is to construct a re-weighted subgraph of  with
with  edges that is a
edges that is a 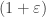 -spectral-approximation to . This will be used later in [ST08c] to construct an ultra-sparsifier. It uses [ST08a] as a subroutine to construct decompositions.
-spectral-approximation to . This will be used later in [ST08c] to construct an ultra-sparsifier. It uses [ST08a] as a subroutine to construct decompositions.
A useful fact shown in Theorem 6.1 (which I am not going to present in details) is that for a graph with smallest non-zero normalized Laplacian eigenvalue  , one can simply sample edges with probability roughly proportional to
, one can simply sample edges with probability roughly proportional to 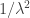 , so that the new graph has
, so that the new graph has 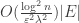 number of (reweighted) edges, and
number of (reweighted) edges, and  -spectrally-approximate the old graph.
-spectrally-approximate the old graph.
As a consequence, to obtain a good sparsifier, the high level idea is to decompose the graph into well-connected (large conductance) clusters 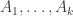 , such that the number of inter-cluster edges is
, such that the number of inter-cluster edges is 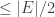 . Then, we can do subsampling for each such cluster (using Theorem 6.1 above), and in the very end contract all clusters and recurse on a graph with edges. Because there are only logarithmic number of levels, this gives a good sparsifier with almost linear number of edges, at least for unweighted graphs. The modifications needed for weighted graphs are not trivial, and elaborated in details in Section 10.2 of [ST08b], which I do not plan to cover.
. Then, we can do subsampling for each such cluster (using Theorem 6.1 above), and in the very end contract all clusters and recurse on a graph with edges. Because there are only logarithmic number of levels, this gives a good sparsifier with almost linear number of edges, at least for unweighted graphs. The modifications needed for weighted graphs are not trivial, and elaborated in details in Section 10.2 of [ST08b], which I do not plan to cover.
BTW, graph decomposition is also called multiway partitioning in the old [ST04] paper.
Conductance: Two Different Notions
Before going into details, there is an important comment to make about conductance in graph  . When talking about the conductance of a cut
. When talking about the conductance of a cut  , it is simply
, it is simply  . Similarly we can also define that of an induced subgraph
. Similarly we can also define that of an induced subgraph  , which is
, which is  . Now comes to an important notion, that is the conductance of a set
. Now comes to an important notion, that is the conductance of a set  , it is
, it is 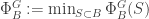 .
.
In short, the conductance of a cut measures the connectivity of a cut, while the conductance of a set gives a lower bound of conductance for all possible cuts that divides the set . I’d love to thank Adrian Vette and Vahab Mirrokni who made this point clear to me in a different project.
Ideal Graph Decomposition
Theorem 7.1 in this paper actually gives a good graph decomposition. It is a constructive proof but relies on an oracle to exact sparsest cut solver, which is NP-hard. It gives some insight to the final solution so I’d love to present its proof here.
Formally, Theorem 7.1 says says that for any graph , one can decompose it into clusters with at most  inter-cluster edges and each cluster has conductance
inter-cluster edges and each cluster has conductance  . This theorem relies on an important lemma:
. This theorem relies on an important lemma:
Lemma 7.2. Given graph with parameter  , and given a subset , let
, and given a subset , let 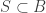 be a set maximizing
be a set maximizing  among those satisfying: (C.1)
among those satisfying: (C.1)  and (C.2)
and (C.2)  . Then, if
. Then, if  for
for  , then
, then  .
.
An interpretation of this Lemma 7.2 is that, if one finds the maximum set  with the conductance upper bound
with the conductance upper bound  , then the other side of the cut
, then the other side of the cut 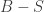 will not only have a good cut conductance
will not only have a good cut conductance 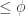 , but also have a good set conductance
, but also have a good set conductance  .
.
The main body of [ST08b] will actually use Lemma 7.2 for the case when  is a very small constant, and the proof of Lemma 7.2 is just by contradiction: suppose does not have a large set conductance, then one can find a cut
is a very small constant, and the proof of Lemma 7.2 is just by contradiction: suppose does not have a large set conductance, then one can find a cut  with small conductance, and one can show that
with small conductance, and one can show that  also satisfies
also satisfies 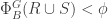 and contradicting the maximality of .
and contradicting the maximality of .
Now comes to the final (but ideal) algorithm to decompose by calling procedure idealDecomp(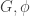 ). Procedure idealDecomp(
). Procedure idealDecomp(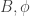 ) first checks if
) first checks if 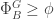 , if so then return . Otherwise, let be the maximum subset satisfying Lemma 7.2. If
, if so then return . Otherwise, let be the maximum subset satisfying Lemma 7.2. If  then recurse on both sides by calling idealDecomp(
then recurse on both sides by calling idealDecomp( ) and idealDecomp(
) and idealDecomp(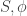 ). If
). If  , then recurse only on the smaller side, because the larger side is guaranteed by Lemma 7.2 to have a large conductance
, then recurse only on the smaller side, because the larger side is guaranteed by Lemma 7.2 to have a large conductance 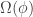 .
.
This algorithm has 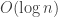 number of layers. On each layer, it will add
number of layers. On each layer, it will add  number of edges to the cut. Since we will set
number of edges to the cut. Since we will set  , the final number of edges on the cut is upper bounded by , so Theorem 7.1 is proved.
, the final number of edges on the cut is upper bounded by , so Theorem 7.1 is proved.
In my next post tomorrow, I am going to show the more exciting proof of constructing the same graph decomposition, in almost linear time using only approximate (but local) sparsest cut solvers from [ST08a].

