
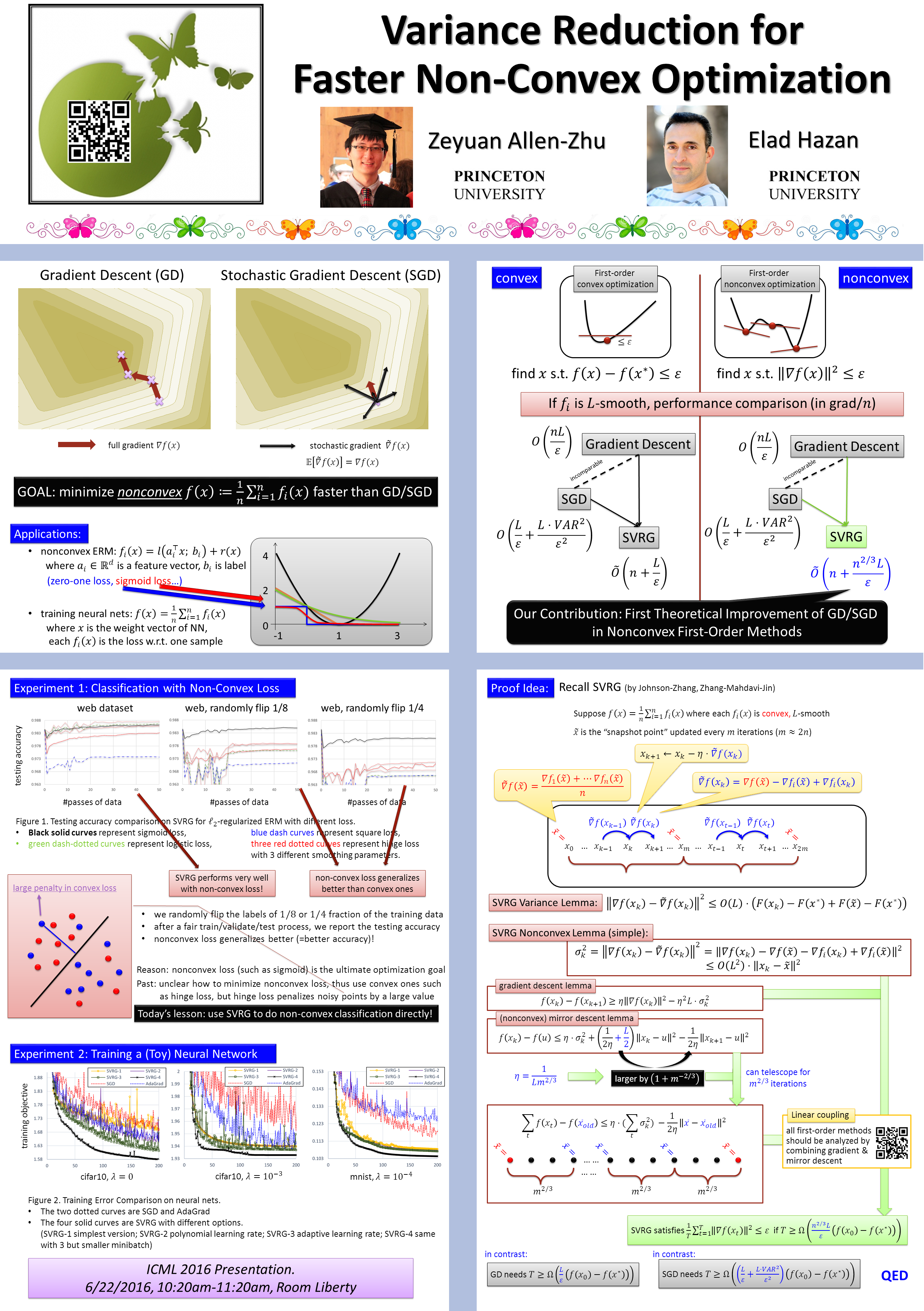
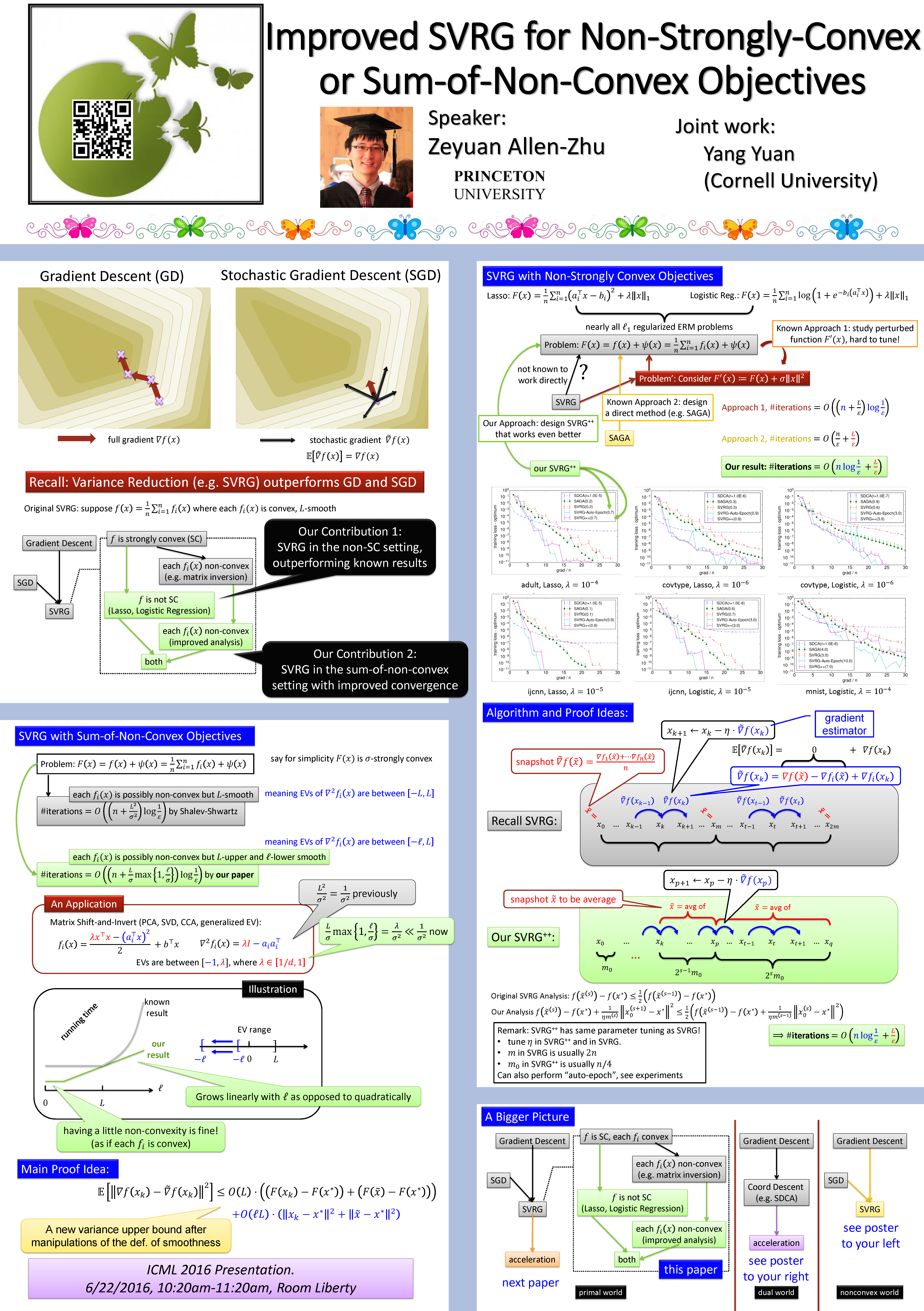
Thanks everyone for attending. In this post I’d like to provide a platform for future discussions of my talk on “Recent Advances in Stochastic Convex and Non-Convex Optimization”. The link for the talk website is here: http://people.csail.mit.edu/zeyuan/topics/icml-2017, and the video (with my personal recording) is already online. Continue reading


 using first-order methods, if full gradients
using first-order methods, if full gradients  are too costly to compute at each iteration, there are two alternatives that can reduce this per-iteration cost. One is to use a (random) coordinate gradient
are too costly to compute at each iteration, there are two alternatives that can reduce this per-iteration cost. One is to use a (random) coordinate gradient 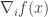 , and the other is to use a stochastic gradient
, and the other is to use a stochastic gradient  satisfying
satisfying ![\mathbb{E}[\tilde{\nabla} f(x)] = \nabla f(x)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctilde%7B%5Cnabla%7D+f%28x%29%5D+%3D+%5Cnabla+f%28x%29&bg=ffffff&fg=333333&s=0&c=20201002) .
.Blogroll
Archives
- August 2017 (1)
- January 2017 (1)
- November 2016 (1)
- July 2016 (2)
- June 2016 (3)
- May 2016 (1)
- June 2012 (3)
- May 2012 (1)
- May 2011 (1)
- March 2011 (1)
- January 2011 (5)
- December 2010 (2)
- November 2010 (2)
Categories
- Readings (13)
- Research (22)
- Algorithm (9)
- Cryptogaphy (2)
- Game Theory (1)
- Learning Theory (6)
- Optimization (8)
- Story (2)
- Uncategorized (1)
